













Among the list of challenges organizations often encounter when adopting advanced tools like artificial intelligence (AI) and machine learning (ML), one that can easily be overlooked is the need for high-performance networking. Specifically, networking that provides both high bandwidth and low latency.
Without high bandwidth, intensive AI and ML workloads don’t have the horsepower needed to run efficiently. Consider how annoying it is when a YouTube video stops to buffer, then amplify that annoyance by 1000x.
Similarly, not having low latency would undermine the effectiveness of AI tools such as chatbots, leading to frustration for users. And attempting to use even more advanced tools, such as predictive analytics models, would deliver results at such a slow pace they would essentially be too outdated to be used at all.
So how do organizations ensure they have enough bandwidth in place while also reducing latency to as close to zero as possible? In most modern datacenters, the key is spine leaf architecture.
An overview of spine leaf architecture
Traditional datacenters were constructed with a three-tier architecture consisting of core routers, distribution (or aggregation) switches, and access switches.
In order to reduce the potential for a condition known as a broadcast storm, which severely disrupts the normal operation of the network, a protocol named Spanning Tree was typically implemented. Spanning Tree helps prevent network loops which cause broadcast storms, but it has several issues, including slow convergence times which can result in the unnecessary disruption of network traffic.
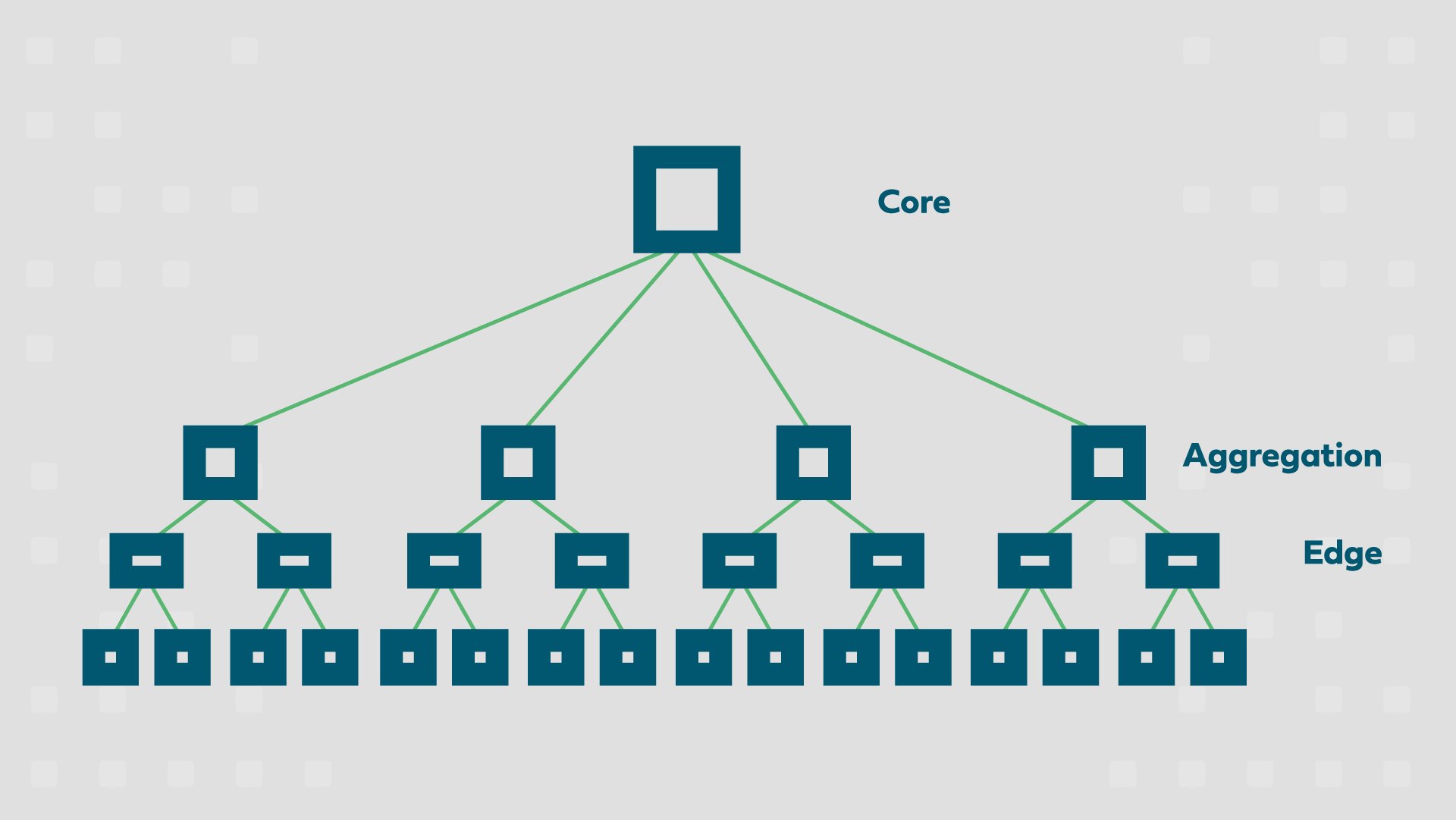
While this three-tier structure was effective, it had some rather severe drawbacks, including high latency and energy needs. Put another way, it could be slow and a power hog.
Spine leaf architecture, in comparison, reshuffles the network topology to greatly reduce latency by cutting down the number of hops between endpoints within a datacenter. The leaf nodes are where all of your compute and storage resources are connected (access layer), and each of these leaf nodes are connected to the spines in the datacenter in order to make the resources connected to the leaf nodes one hop away from each other.
To help wrap your brain around this, here’s a basic topology diagram:
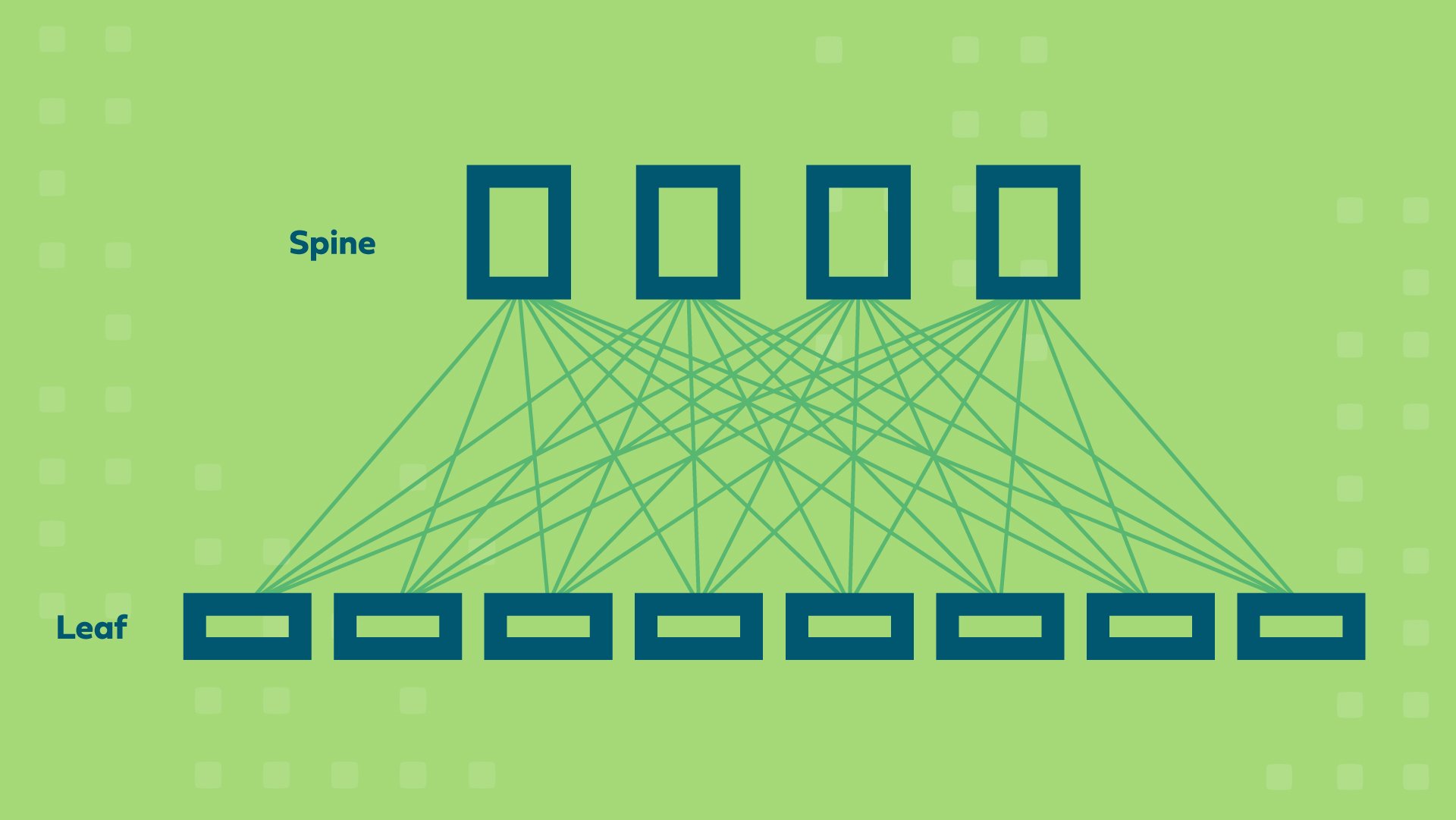
Beyond the minimal latency, spine leaf architecture is highly scalable and fault tolerant. If you start out with, say, 16 leaf nodes connected to 2 spines, you can easily expand that to 32 leaf nodes and 4 spines as your needs change.
This scalability also means you can increase the amount of your bandwidth without the need to grow the number of racks in your datacenter. Multiple connections can be made between the spine nodes and leaf switches. This allows for equal cost multi-pathing between various nodes—basically, you’re able to leverage the bandwidth across all of your links in a much more efficient way, which dramatically increases throughput.
For example, if you outgrow your bandwidth capacity provided by two leaf-to-spine links, it’s relatively simple to add two more links to grow and scale the amount of bandwidth you have available.
And when properly implemented, the high degree of fault tolerance provided by a spine leaf architecture means the impact from the loss of a link or device is minimal and rarely impacts the user experience. This high level of fault tolerance also facilitates the ability to perform network maintenance activities without service outages.
Getting the right networking in place
Ultimately, whatever shape your networking takes will depend on some key factors.
One is your organization’s overall readiness to adopt advanced analytics tools like AI and ML. Another is what your eventual AI and ML workloads will need—how much bandwidth, how frequently your need results from your models, and more.
You can learn more about how you can get the right infrastructure in place for advanced analytics tools in our comprehensive AI and ML resource. And if you’re ready to build out your organization’s advanced analytics capabilities—not just when it comes to networking, but for every facet of the process—contact one of our experts.

.png?width=352&name=redapt_powerscale_AI_hero%20(1).png)
