













Kubernetes (K8s) is a Container Orchestration Platform that was influenced by Google engineers experience developing and working with Borg. As many know, Google has been running containers at large scale for more than a decade. K8s is completely open-source, API Driven, written in GoLang, has lots of community support, and hundreds of 3rd party add-ons.
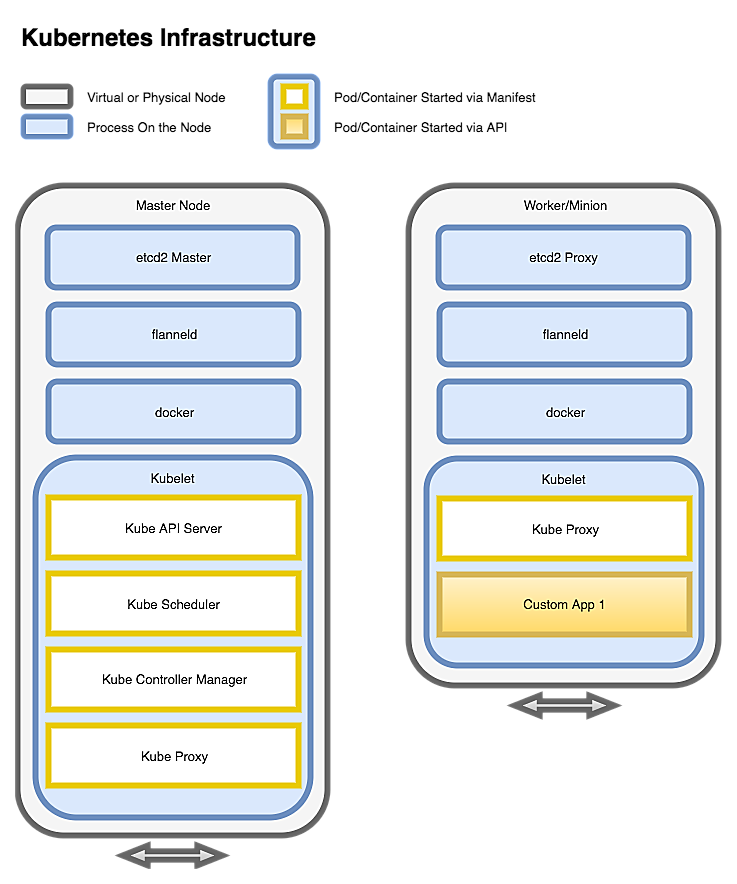
K8s from the outside consists of three major components: etcd cluster, master server(s), and minion worker node(s). It is common to see the master services run on the same nodes as the etcd cluster, which is a distributed key-value store.
The master server runs the API, the Controller Manager, and the Scheduler. The API uses the etcd service to store any state related to running K8s. This includes the nodes in the cluster, what containers are running where, what volumes are attached to containers, secrets, config maps, etc. The controller manager embeds the core control loop for K8s, and constantly tries to make the real-world match the expected state. The scheduler is used to ensure that pods are scheduled according to their affinity, maintain data locality, etc.
The minion worker nodes are effectively the pool of resources that can be consumed by running containers. Each minion should have K8s labels designating its failover zone, and name. You can make use of these labels by defining affinity when distributing containers across the system.
 In K8s, a container or a specialized group of containers, are collectively run in what is called a Pod. Each Pod runs on a single minion host with an overlay network, and thus has its own IP address. It's common to run many similar pods for load and redundancy spread throughout the minion hosts.
In K8s, a container or a specialized group of containers, are collectively run in what is called a Pod. Each Pod runs on a single minion host with an overlay network, and thus has its own IP address. It's common to run many similar pods for load and redundancy spread throughout the minion hosts.
While it is possible to create one pod at a time. K8s provides various mechanisms for controlling the number of replicas and location of pods, as well as auto-restart on delete/failures. A Replica Set can be defined in place of a pod definition, and the number of replicas becomes a tunable field. If the node is killed and a pod dies, the Controller Manager and Scheduler will work to re-schedule a new pod, until the requirements of the Replica set are met.
Beyond a simple Replica Set, K8s also has the concept called a Deployment. In the current iteration of K8s, the deployment effectively manages replica sets. When rolling out new images via Deployment, a 'green' Replica Set is created, while the old Replica Set is 'blue'; The green Replica Set scales up incrementally, while simultaneously scaling down the blue Replica Set. You can also stand up two equal size Replica Sets, cut traffic over, and then delete the old Replica Set, for non blue-green rollouts.
Launching many pods is great, but what about routing traffic to all of the pods as I adjust the replica counts? To handle this, K8s introduces a concept called a Service. A service has a few different types depending on whether load balancing is necessary, and how ports are translated/specified. Routing generally happens via K8s pod labels and selectors.
No matter what type of resource you create in Kubernetes, it can be created with a json or yml file, which can be kept in version control. This is useful for rapid re-deploys, CICD, and tracking changes to pod Definition/Environment over time, for the application.

