
Apache Spark is the Taylor Swift of big data software. The open source technology has been around and popular for a few years. But 2015 was the year Spark went from an ascendant technology to a bona fide superstar".
Apache Spark is an open-source cluster-computing framework. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since. Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
Apache Spark is fast, easy to use, and a general engine for large-scale data processing and analysis. It provides parallel distributed processing on commodity hardware. It provides a comprehensive, unified framework for Big Data analytics.
Spark Core is the foundation of the overall project. It provides distributed task dispatching, scheduling, and basic I/O functionalities, exposed through an application programming interface (for Java, Python, Scala, and R) centered on the resilient distributed dataset (RDD).
Spark MLlib is a distributed machine learning framework on top of Spark Core. Many common machine learning and statistical algorithms have been implemented and are shipped with MLlib which simplifies large scale machine learning pipelines. This blog post will focus on MLlib.
Spark use cases
- Fraud detection: Spark streaming and machine learning applied to prevent fraud.
- Network intrusion detection: Machine learning applied to detect cyber hacks.
- Customer segmentation and personalization: Spark SQL and machine learning applied to maximize customer lifetime value.
- Social media sentiment analysis: Spark streaming, Spark SQL, and Stanford's CoreNLP wrapper helps achieve sentiment analysis.
- Real-time ad targeting: Spark used to maximize Online ad revenues.
- Predictive healthcare: Spark used to optimize healthcare costs.
Real-life examples of Spark in industry
Uber
- Business Problem: A simple problem of getting people around a city with an army of more than 100,000 drivers and to use data to intelligently perfect the business in an automated and real-time fashion.
- Requirements:
- Accurately pay drivers per trips in the dataset
- Maximize profits by positioning vehicles optimally
- Help drivers avoid accidents
- Calculate surge pricing
- Solution: Use Spark Streaming and Spark SQL as the ELT system and Spark MLlib and GraphX for advanced analytics
- Reference: Talk by Uber engineers at Apache Spark meetup: https://youtu.be/zKbds9ZPjLE
Netflix
- Business Problem: A video streaming service with emphasis on data quality, agility, and availability. Using analytics to help users discover films and TV shows that they like is key to Netflix's success.
- Requirements:
- Streaming applications are long-running tasks that need to be resilient in Cloud deployments.
- Optimize content buying
- Maintain Netflix's acclaimed personalization algorithms
- Solution: Use Spark Streaming in AWS and Spark GraphX for recommendation system.
- Reference: Talk by Netflix engineers at Apache Spark meetup: https://youtu.be/gqgPtcDmLGs
- Business Problem: Provide a recommendation and visual bookmarking tool that lets users discover, save, and share ideas. Also get an immediate view of Pinterest engagement activity with high-throughput and minimal latency.
- Requirements:
- Real-time analytics to process user's activity.
- Process petabytes of data to provide recommendations and personalization.
- Apply sophisticated deep learning techniques to a Pin image in order to suggest related Pins.
- Solution: Use Spark Streaming, Spark SQL, MemSSQL's Spark connector for real-time analytics, and Spark MLlib for machine learning use cases.
- Reference: https://medium.com/@Pinterest_Engineering/real-time-analytics-at-pinterest-1ef11fdb1099#.y1cdhb9c3
If your company does not have the resources the above companies have to devote to machine learning, Redapt is here to help!
Spark and its speed
- Lightning fast speeds due to in-memory caching and a DAG-based processing engine.
- 100 times faster than Hadoop's MapReduce for in-memory computations and 10 time faster for on-disk.
- Well suited for iterative algorithms in machine learning.
- Fast, real-time response to user queries on large in-memory data sets.
- Low latency data analysis applied to processing live data streams
Spark is easy to use
- Provides a general purpose programming model using expressive languages like Scala, Python, and Java.
- Existing libraries and API makes it easy to write programs combining batch, streaming, interactive machine learning and complex queries in a single application.
- An interactive shell (aka REPL) is available for Python and Scala
- Built for performance and reliability; written in Scala and runs on top of Java Virtual Machine (JVM).
- Operational and debugging tools from the Java stack are available for programmers.
Getting started with Apache Spark
The official Apache Spark website provides detailed documentation on how to install Apache Spark. In this blog post, I will assume you already have Spark installed. However, if you wish, I have also created a Docker image of everything you will need to start a Docker container running Apache Spark, along with some other tools and packages used in these blog posts (e.g., R, iPython, Pandas, NumPy, matplotlib, etc.).
If you want to follow along with the examples provided, you can either use your local install of Apache Spark, or you can pull down my Docker image like so (assuming you already have Docker installed on your local machine):
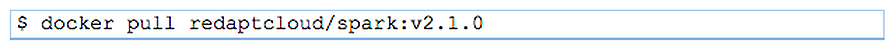 Note: The above Docker image size is ~2.66 GB, so it might take a while to download, depending on your Internet speed.
Note: The above Docker image size is ~2.66 GB, so it might take a while to download, depending on your Internet speed.
Then start a Docker container from the above image with:
 Note: The above container will have access to files in the directory the Docker command was run from and mounted at `/data` inside the container. Since it is not a good idea to store your datasets inside Docker containers, this blog post will assume the datasets used in this article are found in the same directory as where you ran the above Docker command (see below for details on the datasets in question).
Note: The above container will have access to files in the directory the Docker command was run from and mounted at `/data` inside the container. Since it is not a good idea to store your datasets inside Docker containers, this blog post will assume the datasets used in this article are found in the same directory as where you ran the above Docker command (see below for details on the datasets in question).
Apache Spark will be installed under `/spark` and all of Spark's binaries/scripts will be in the user path. As such, you can start, say, pyspark by simply executing `pyspark` from your current working directory.
A simple example using Apache Spark MLlib
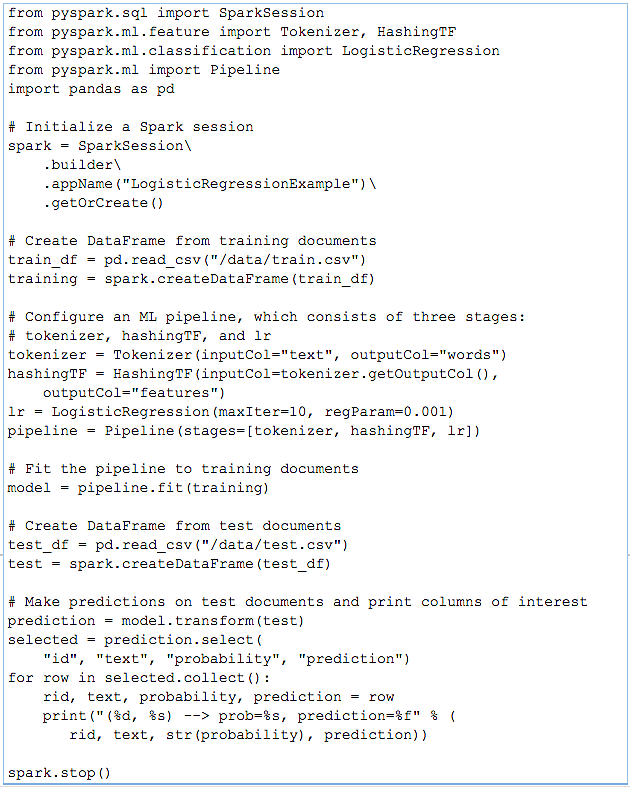
Logistic Regression is part of a class of machine learning problems, generally referred to as function approximation. Function approximation is a subset of problems that are called “supervised learning problemsâ€. Linear regression is the most common (and basic) algorithm in this class. Logistic regression (a classifier cousin of linear regression) is especially useful for text classification. It is fast, simple to use, and provides optimum or near-optimum performance on the vast majority of predictive analytics problems encountered in datasets with categorical targets (i.e., the target of prediction is a yes/no, true/false, present/absent, etc. outcome). For example, in text classification, we can ask Do the documents in the dataset have a word/phrase or not? The following is a very simple example of using logistic regression for text classification.
Let's pretend we have a very simple dataset where we want to do some basic text document classification. Our dataset consists of a comma-separated values (CSV) file with one text document per line in the file. Our example dataset is just lines that either contain the word "spark" or do not. This will be the target of our MLlib training and will be what we use to create our ML model. Our training dataset has three columns: document ID (`id`), the text of the document (`text`), and a `label` value of 1.0 or 0.0 for whether or not the line has our target word "spark".
 The text document classification pipeline we will use has the following workflow:
The text document classification pipeline we will use has the following workflow:
- Training workflow: Input is a set of text documents, where each document is labelled. Stages while training the ML model are:
- Split each text document (or lines in our `train.csv` file) into words;
- Convert each document's words into a numerical feature vector; and
- Create a prediction model using the feature vectors and labels.
- Test/prediction workflow: Input is a set of text documents and the goal is to predict a label for each document. Stages while testing or making predictions with the ML model are:
- Split each text document (or lines in our `test.csv` file) into words;
- Convert each document's words into a numerical feature vector; and
- Use the trained model to make predictions on the feature vector.
Start up the pyspark REPL (interactive shell):
![]() Note: The following commands should be run from within the pyspark REPL. The following code is based off of the example scripts provided in the Spark tarball.
Note: The following commands should be run from within the pyspark REPL. The following code is based off of the example scripts provided in the Spark tarball.
 The above simple script should return the following for Spark MLlib predictions for the test documents:
The above simple script should return the following for Spark MLlib predictions for the test documents:
 The above output contains the results of using logistic regression with Spark MLlib to make text document classifier predictions. Each line in the output provides the following:
The above output contains the results of using logistic regression with Spark MLlib to make text document classifier predictions. Each line in the output provides the following:
- The input line (e.g., 4, spark i j k);
- The probability that the line does not and does contain the target word (e.g., ~16% does not, ~84% does); and
- The prediction made by Spark (1.0 = true; 0.0 false)
So, for this very simple example, Spark MLlib made perfect predictions (i.e., all documents with the word "spark" in them were correctly labeled). Of course, with such a simple dataset, the results are not that interesting (or useful, really). The idea of this first blog post in the series was to provide an introduction to Apache Spark, along with a "Hello, world"-type example.
Part 2 of this blog series on Machine Learning will provide a more complicated (and interesting and useful) example of using Apache Spark for Machine Learning.

Get Your Free AI/ML Playbook.
Learn how to overcome the challenges and achieve success as you adopt artificial intelligence and machine learning.



